Mekanisme service recovery pada slot adalah serangkaian proses yang memastikan layanan pada sebuah slot dapat pulih dan kembali berfungsi ketika terjadi kegagalan. Mekanisme ini merupakan fondasi ketahanan sistem, terutama pada platform dengan tingkat ketersediaan tinggi. Untuk memahaminya secara utuh, kita perlu melihatnya dari beberapa sudut pandang. Berikut artikel ini akan membahas tentang Cara memahami mekanisme service recovery pada slot.
1. Pahami Tiga Mode Dasar Recovery
Cara paling mudah untuk memulai adalah dengan memahami tiga mode konfigurasi recovery yang umum digunakan pada sistem berbasis slot . Mode-mode ini menentukan bagaimana sistem akan bereaksi ketika sebuah fault terdeteksi :
-
Mode
none: Dalam mode ini, slot akan mempertahankan statusnya saat ini, terlepas dari fault yang terjadi. Slot tidak di-reset. Meskipun terlihat sederhana, mode ini tidak menjamin slot akan tetap beroperasi; fault diabaikan dan hanya dicatat ke dalam log . -
Mode
reset: Mode ini mengonfigurasi slot yang bermasalah untuk melakukan reset secara otomatis saat fault terdeteksi. Untuk slot reguler, reset dilakukan maksimal lima kali sebelum slot akhirnya dimatikan secara permanen. Sementara itu, slot yang berperan sebagai master atau backup dapat di-reset berkali-kali dan tidak dimatikan . -
Mode
shutdown: Mode ini mengonfigurasi sistem untuk mematikan semua slot yang dikonfigurasi dengan mode shutdown ketika fault terdeteksi. Semua port pada slot tersebut diambil offline, namun slot tetap operasional untuk keperluan debugging. Slot akan tetap berada dalam status shutdown bahkan setelah reboot atau power cycle, sampai administrator secara eksplisit membersihkan status shutdown tersebut .
Ketiga mode ini menunjukkan bahwa tidak ada pendekatan tunggal untuk recovery; pilihan mode harus disesuaikan dengan tingkat kritisitas layanan pada slot tersebut.
2. Pahami Mekanisme Spare Slot dan Failover Otomatis
Untuk sistem yang membutuhkan pemulihan cepat tanpa intervensi manual, mekanisme spare slot adalah solusi yang umum digunakan. Dalam arsitektur ini, satu atau lebih slot disediakan khusus sebagai cadangan (spare slot) .
Berikut alur kerjanya:
-
Manajemen Informasi Slot: Dua perangkat lunak kontrol mengelola informasi slot yang mencakup informasi path, alokasi sumber daya, dan konfigurasi perangkat .
-
Deteksi dan Peralihan: Ketika kegagalan terdeteksi pada slot utama, sistem akan memperbarui informasi path-nya. Perangkat lunak kontrol kemudian memerintahkan switch untuk mengalihkan koneksi dari slot yang gagal ke spare slot yang telah ditentukan . Proses ini memungkinkan perangkat atau layanan tetap terhubung tanpa waktu henti yang signifikan .
-
Proses Restorasi: Setelah slot yang gagal diperbaiki atau diganti, slot tersebut dapat dikembalikan fungsinya sebagai spare slot melalui proses restorasi . Proses ini memastikan bahwa kemampuan failover tetap tersedia untuk kejadian kegagalan di masa depan.
Keuntungan utama pendekatan ini adalah biaya multiplexing yang lebih rendah, karena satu spare slot dapat menggantikan beberapa slot utama, dan tidak diperlukan fungsi khusus tambahan karena konfigurasi perangkat kerasnya sama .
3. Pahami Recovery pada Sistem Terdistribusi dan Data
Dalam sistem terdistribusi, memahami recovery berarti memahami bagaimana koordinasi dan konsistensi data dipulihkan.
-
Recovery Subslot Allocation: Dalam sistem yang menggunakan wormhole routing, mekanisme ini digunakan untuk mengelola alokasi subslot untuk recovery. Setiap wormhole lokal mengakses struktur data replikasi untuk menemukan subslot yang tersedia ketika diperlukan untuk memulihkan replika yang dicurigai gagal .
-
Slot Recovery pada Database: Pada sistem file terdistribusi seperti OCFS2, recovery bersifat asinkron. Ada potensi konflik di mana satu node dapat melakukan mount dan recover slot sebelum recovery thread dari node lain menjangkaunya. Solusinya adalah dengan melacak “generasi recovery” pada journal inode. Recovery thread akan membandingkan generasi yang ada di disk dengan yang di-cache-nya sebelum mencoba mengunci slot, sehingga ia dapat melewati recovery jika ternyata sudah dilakukan oleh node lain .
-
Recovery Callbacks: Sistem manajemen lock terdistribusi (seperti DLM) menyediakan callback untuk mengoordinasikan recovery ketika sebuah node gagal. Callback
recover_slot()dipanggil untuk mengidentifikasi node dan memulai recovery, sementararecover_done()dipanggil ketika semua node telah menyelesaikan proses recovery . Memahami tahapan ini penting untuk mengikuti alur recovery di tingkat klaster.
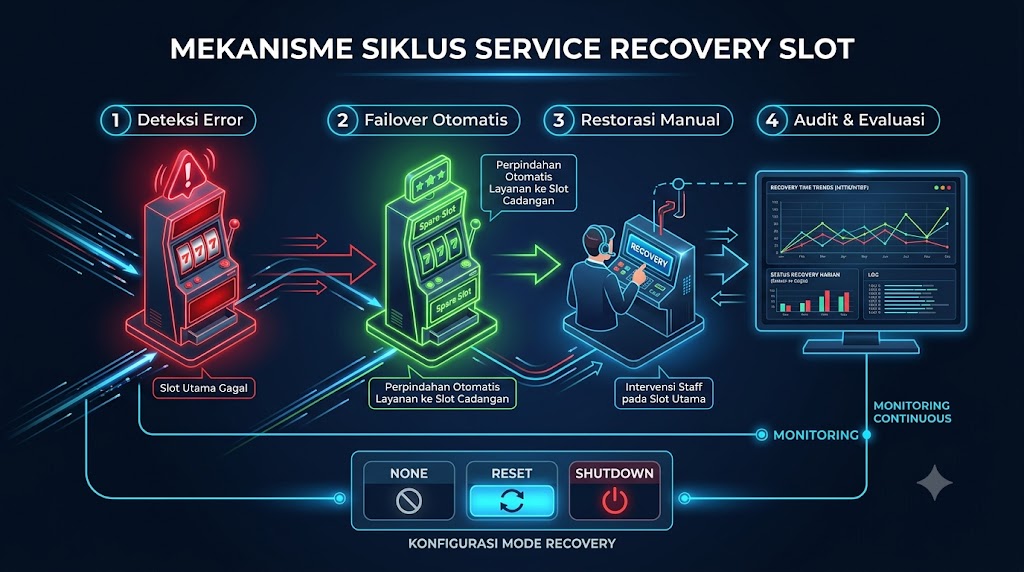
4. Pahami Siklus Penuh: Dari Deteksi hingga Konfirmasi
Untuk memahami mekanisme secara menyeluruh, penting untuk melihat siklus recovery dari awal hingga akhir. Sebuah sistem recovery yang baik tidak hanya berhenti pada proses teknis, tetapi juga mencakup audit dan evaluasi.
1. Deteksi dan Pelaporan Error:
Saat sebuah mesin slot (atau sistem komputasi) mendeteksi error—misalnya, dampak fisik atau lonjakan voltase di luar batas—fungsi permainan akan dihentikan untuk mencegah kerusakan lebih lanjut . CPU utama mengirimkan sinyal deteksi error ke terminal PTS, yang kemudian meneruskannya ke server manajemen staf .
2. Proses Pemulihan dan Verifikasi:
Setelah error teratasi, staf akan menekan tombol “recovery completion button” yang terletak di dalam kabinet mesin . Tindakan ini melepaskan kunci pada fungsi permainan dan mengirimkan sinyal “recovery selesai” ke terminal PTS .
3. Audit dan Evaluasi:
Ini adalah bagian yang sering terlewat namun sangat penting. Sistem mulai menghitung waktu yang berlalu sejak deteksi error hingga sinyal recovery diterima . Data ini, bersama dengan rekaman video dari staf yang melakukan perbaikan (dari 10 menit sebelum error hingga setelah recovery), dikirim ke server manajemen . Ini memungkinkan evaluasi performa staf dan memverifikasi identitas mereka, serta mengidentifikasi mesin mana yang memiliki waktu recovery tercepat .
Penutup
Memahami mekanisme service recovery pada slot berarti memahami lapisan-lapisan strategi yang saling melengkapi: mulai dari konfigurasi dasar yang menentukan perilaku sistem saat terjadi fault, mekanisme failover otomatis yang meminimalkan downtime, koordinasi di tingkat sistem terdistribusi, hingga siklus audit yang memastikan perbaikan berkelanjutan. Dengan pendekatan ini, Anda dapat mendiagnosis, merancang, dan mengelola sistem yang lebih tangguh.